작동 원리
Drizzle는 원래 SQL 위에 얇은 레이어로 설계되었으며, 최소한의 런타임 오버헤드를 도입했습니다. Prepared Statements와 Relational Queries를 도입함으로써 성능을 크게 향상시켰습니다. 이제 Drizzle는 빠를 뿐만 아니라 탁월한 개발자 경험(DX)을 제공하며, 관계형 쿼리에서 n+1 문제가 발생하지 않습니다.
그렇다면 얼마나 빠를까요? Drizzle가 빠른 걸까요, 아니면 SQL이 빠른 걸까요? 무엇을 측정해야 할까요?
의미 있는 벤치마크란 무엇일까요?
우리는 mitata를 사용해 합성 벤치마크를 수행하며 상당한 시간을 보냈습니다. 모든 것을 하나의 런타임에서 테스트한 후, 별도의 컨테이너에서 테스트하여 GC(가비지 컬렉션)의 교차 영향을 배제했습니다. 커뮤니티에서도 자체 벤치마크를 만들어 Relational Queries의 성능과 행 읽기 병목 현상을 파악하고, 이를 빠르고 효율적으로 개선하는 데 도움을 주었습니다.
우리는 모든 경쟁 제품에 대해 다양한 SQL 방언을 테스트했습니다. SQLite에서 Prisma보다 100배 이상 빠른 경우도 있었지만, 비즈니스와 개발자에게 의미 있는 벤치마크만 공유하고자 했습니다.
비즈니스 관점에서 서버 측 성능에서 가장 중요한 지표는 요청 왕복 시간입니다. Cloudflare Argo와 같은 서비스로 네트워크 지연 시간을 줄일 수는 있지만, 서버 측에서는 대부분 데이터베이스 쿼리가 성능을 좌우합니다.
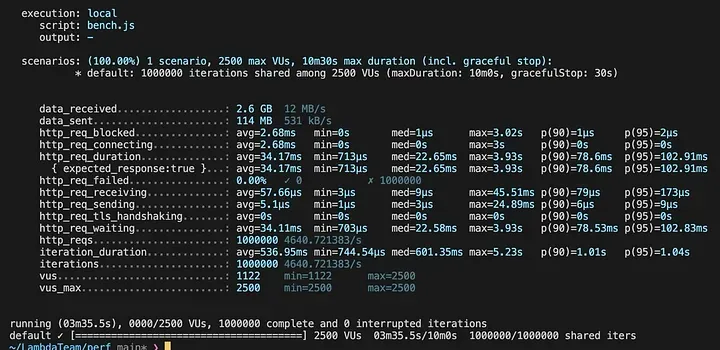
우리는 PostgreSQL 데이터베이스에 약 37만 개의 레코드로 테스트 케이스를 구성하고, 1GB 이더넷에서 실제 E-commerce 트래픽과 유사한 벤치마크를 생성하여 차이를 최소화했습니다. Lenovo M720q에서 Drizzle는 4.6k reqs/s를 처리하면서도 약 100ms의 p95 지연 시간을 유지했습니다.
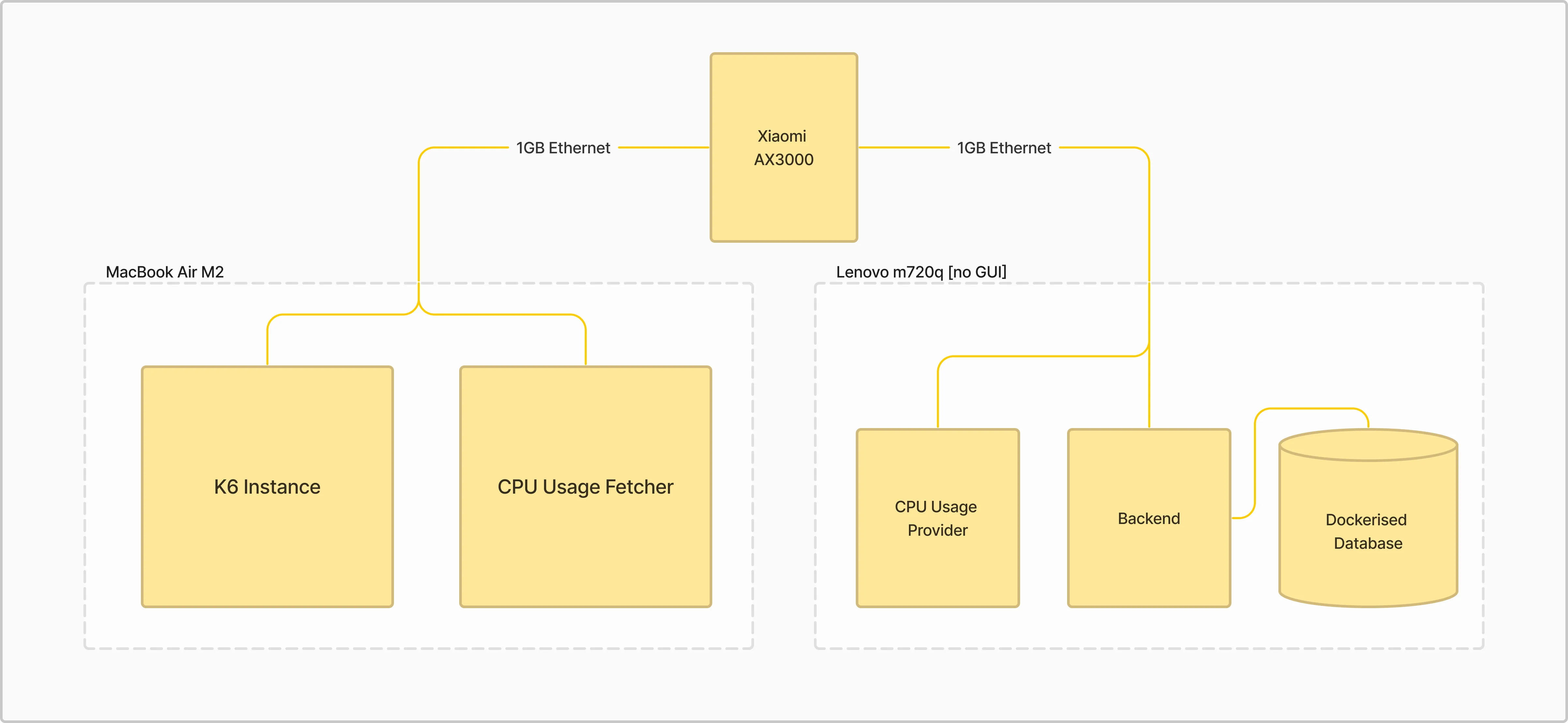
우리는 벤치마크를 2대의 별도 머신에서 실행하여 관찰자가 결과에 영향을 미치지 않도록 했습니다. 데이터베이스로는 42MB의 E-commerce 데이터(약 37만 개 레코드)가 있는 PostgreSQL 인스턴스를 사용했습니다.
K6 벤치마크 인스턴스는 MacBook Air에서 실행되며, 1GB 이더넷을 통해 Intel Core i3-9100T와 32GB RAM이 탑재된 Lenovo M720q로 1M prepared requests를 전송합니다.
여러분도 직접 테스트를 실행해보고 싶다면 아래 지침을 따르세요!
테스트 머신 준비하기
-
pnpm start:docker명령어를 사용해 PostgreSQL이 포함된 도커 컨테이너를 실행합니다. 원하는 데이터베이스 포트는./src/docker.ts파일에서 설정할 수 있습니다:... } const desiredPostgresPort = 5432; // 여기서 포트 변경 main(); -
.env파일에서DATABASE_URL을 할당된 데이터베이스 포트로 업데이트합니다:DATABASE_URL="postgres://postgres:postgres@localhost:5432/postgres" -
pnpm start:seed명령어를 사용해 테스트 데이터로 데이터베이스를 시드합니다. 데이터베이스 크기는./src/seed.ts파일에서 변경할 수 있습니다:... } main("micro"); // nano | micro -
Node 버전 18 이상이 설치되어 있는지 확인하세요.
nvm use 18명령어를 사용할 수 있습니다. -
Drizzle/Prisma 서버를 시작합니다:
## Drizzle pnpm start:drizzle ## Prisma pnpm prepare:prisma pnpm start:prisma
테스트 환경 준비
pnpm start:generate명령어로 HTTP 요청 목록을 생성합니다. 이 명령어는 테스트할 서버에서 실행할 HTTP 요청 목록을./data/requests.json파일로 출력합니다.- k6 부하 테스터를 설치합니다.
./k6.js파일에서 테스트할 서버의 URL을 설정합니다.// const host = `http://192.168.31.144:3000`; // drizzle const host = `http://192.168.31.144:3001`; // prismak6 run bench.js명령어로 테스트를 실행합니다. 🚀